
Peaky Blinders is an award-winning historical drama series produced by BBC Studios. The show is set between the two world wars and is centered around Birmingham, England, starring a notorious gangster family, the Shelbys. After five seasons and nearly half a million ratings in the Internet Movie Database, by now, the Peaky boys, with their signature look, are listed among the Top 100 most popular TV shows on IMDb.
The drama series has already surprised fans with several unexpected deaths and comebacks, so the whole world is watching what the grand finale may bring at the end of February 2022. As an impatient data scientist and Peaky Blinders fan I decided to spoil it a little: I combined network and data science to build a predictive model forecasting the story’s ending for its iconic main character, Tommy Shelby.
In more techie terms, I proposed a binary classification problem using various features and attributes describing the show’s characters, and trained a simple machine learning model to capture those quantitative insights that may separate living characters from deceased ones.
Peaky Blinders data source
As a primary data source, I relied on the fan wiki site, Peaky Blinders Wiki. Once I narrowed the scope down to this data source, the data collection involved two simple steps. First, I crawled the list and biography link of the 118 noted characters and then, I scraped the biography of each character separately.
Turning the show into numbers
The core idea of this predictive project is the following. First, I describe each individual in the show by a set of features that may potentially contain hints on someone’s future fate. These features include measures like the number of episodes they appeared in, or the number of people they met, basically encoding a quantitative fingerprint for everyone. Second, tracked down which of them had already died and who was still alive. Third, I trained a simple machine learning model that is able to differentiate between the living and the dead just by looking at their feature parameters (see details below). Finally, I ask the trained model to predict the expected fate of Tommy Shelby.
In more detail, I use the following types of features describing each character, split into three major categories that may influence their time alive on screen: features associated with someone’s activity and presence in the show, the individual’s story based on their written biography, and the character’s vitality to the social structure of the story measured by network features. In more detail:
1. Screenplay features. This group of features characterizes aspects of what we see on the screen: the first episode and the number of episodes each character appeared in. While for some characters, the data source contains additional information, like allegiance or family status, I aimed to keep the number of studied characters high to provide as much training data for the machine learning model as possible, dropping just a few because of missing feature values. This way, I ended up with 83 characters with screenplay features.
Studying these numbers, it turns out that the characters are present, on average, in eight episodes – that’s almost one-and-a-half seasons! Additionally, also not surprisingly, the largest introduction number of new characters (16 in the current selection) was in the very first episode, followed by S02E02 with five, S0201 and S0301 with four new significant characters each.
2. Textual biography features. These attributes try to quantify the personal stories by computing a few simple and widely used metrics about the individuals’ biography texts: sentiment scores and readability. While the latter accounts for the complexity of one’s background story, the compound sentiment score measures the overall sentiment level. Besides that, I added its breakdown: the level of positive, negative, and neutral sentiments, using the popular vaderSentiment tool. Finally, I computed the total length of each biography measured in the number of sentences and characters as well. Due to the data availability, these features could be curated for 86 characters.
When ranking characters based on their negative sentiment, among the top were those with tragic stories: Greta Jurossi, the ex-lover of Tommy, the troubled ex-soldier Danny Whizz-Bang, and the major villain, Father Hughes. While on the brighter side, both Grace Shelby and her in-and-out perfect first husband, Clive Macmillan, are amongst the most positive characters mentioned.
3. Social features. As the Peaky Blinders have a non-trivial, dynamic social system with alliances forming and breaking, enemies coming and going, and even conflicts occurring within families, I presumed network connections could have a valuable contribution to one’s fate as well.
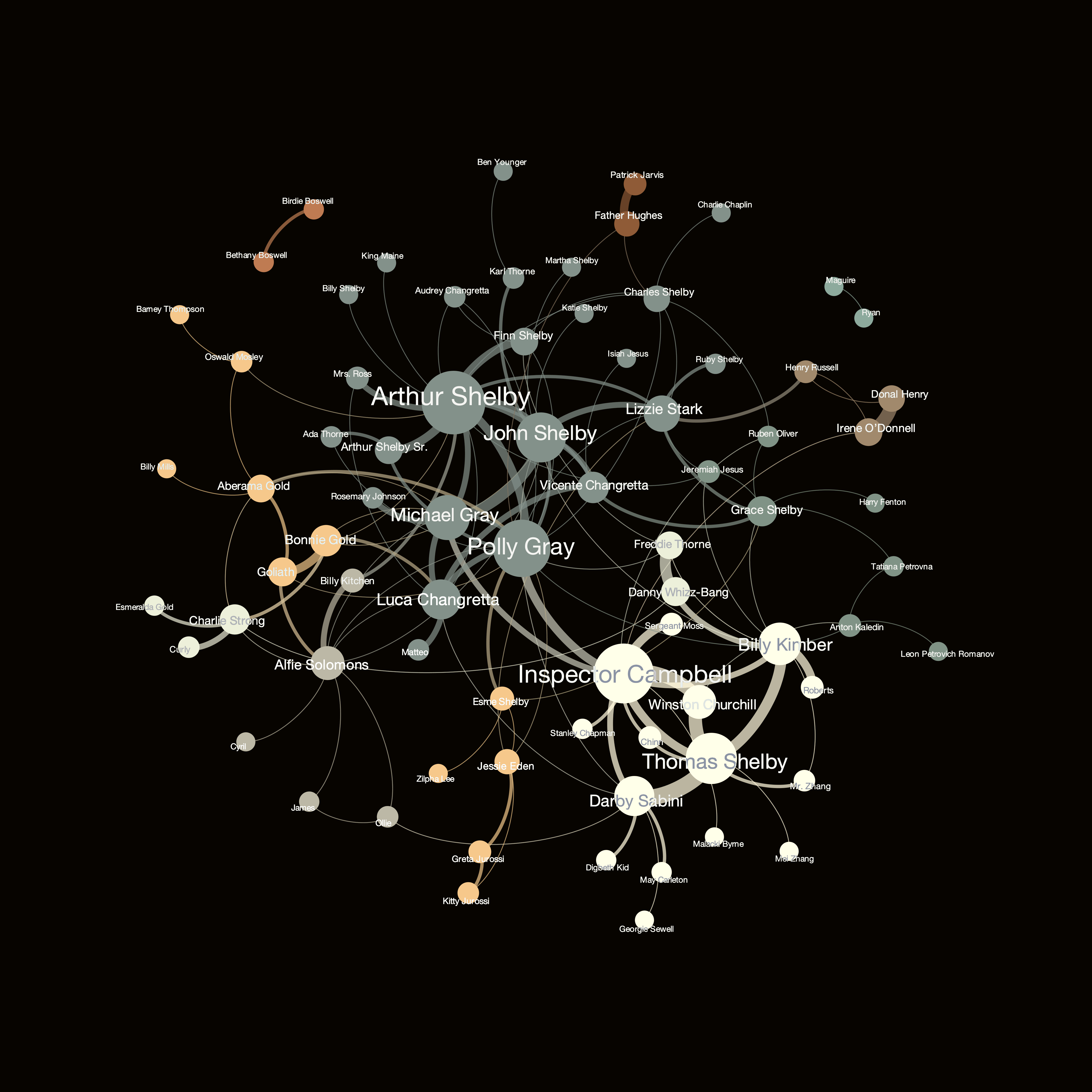
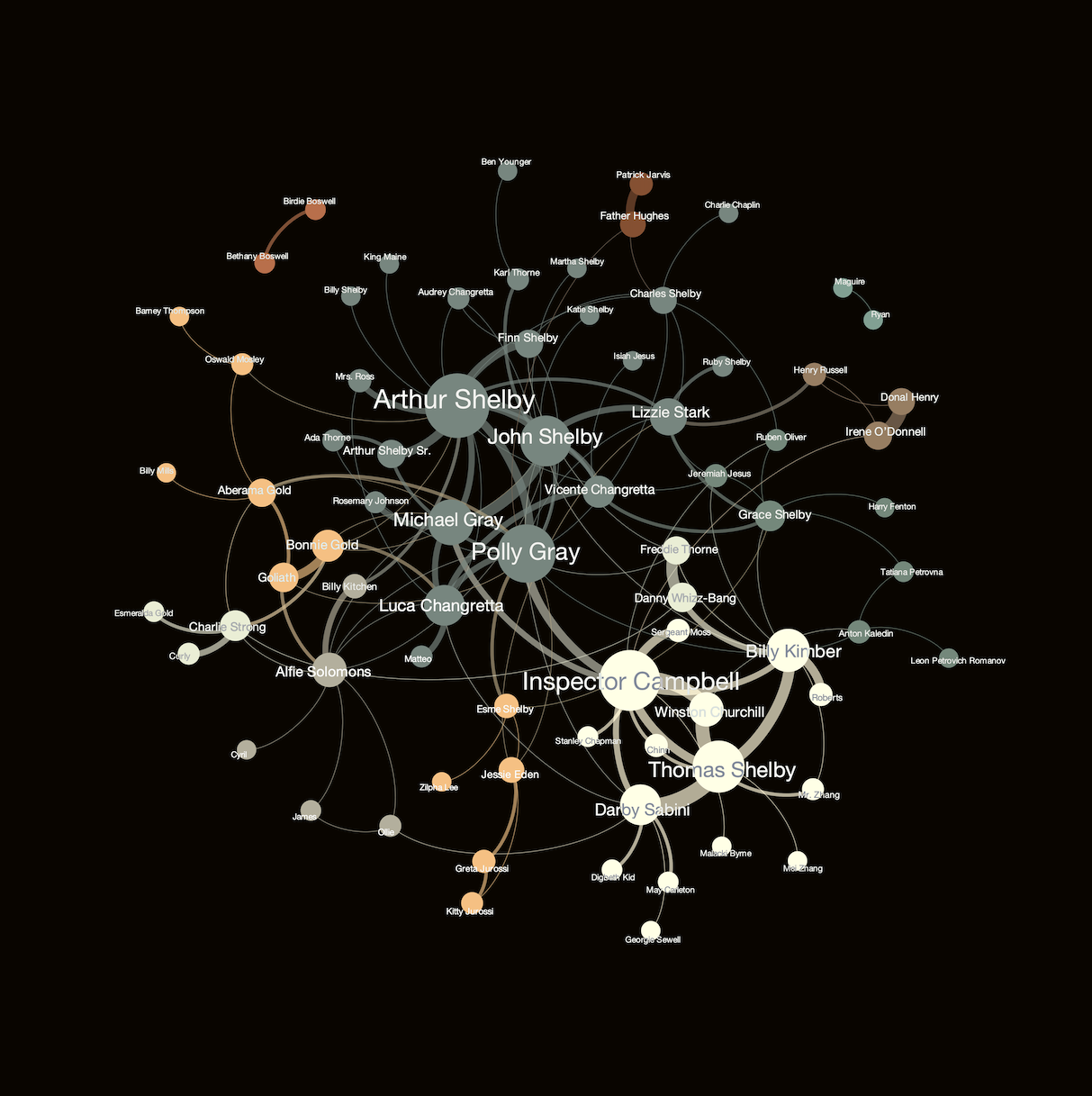
To capture this, I built the social network of the characters where each of them is represented by a node of the graph. In this network, there is a link between the two characters if at least one of them has a reference (hyperlink) to the other one in their biography profile, illustrating the connection between their stories. For instance, Tommy’s biography site references the profiles of his siblings in its first paragraph.

With this simple definition, I arrived at 89 nodes and 298 connections. After trimming down the network from noisy edges (removing the ones that have a likelihood of being present near to random), the network shrinks to 75 nodes and 135 links. Interestingly, in the filtered network, even the famous couple, Tommy and Grace got separated, due to the smaller weight of their connection compared to the intensity of Tommy’s other connections! Unfortunately, this love story got overruled by statistics. To curate actual features, I computed the following network measures on the filtered graph:
- Degree centrality, capturing the number of connections someone has
- Betweenness centrality, which quantifies the presence of bridges in a network
- Clustering coefficient, measuring how densely someone’s connections are linked to each other
- Closeness centrality, showing how close (in terms of graph hops/handshake) someone is to the center of the network
The network graph is visualized in Figure 1, and allows us to make several observations immediately. For instance, we can clearly see the pronounced role of the Shelby family – interestingly, Tommy is separated from the majority and more surrounded by his early enemies than friends (e.g., Campbell, Sabini, or Kimber). Tommy being apart from his ‘home community’ also shows that he is kind of an explorer, being in the frontline, while the family back home is more focused on running the businesses already set. Additionally, we can see a few other smaller communities, such as the gang around Aberama Gold, connecting them via the box-match plots to the crew of Alfie Solomons.
Modeling and results: SPOILER ALERT…serious spoilers follow!
After putting all the features together, I ended up with 59 individuals: 38 alive and 21 deceased, all of them described by 13 numerical features. As the target variable, being dead or alive, is a binary, I used a binary classifier, the popular XGBoost, set up for imbalanced classification. I trained the XGBoost model with grid search with three repeats of stratification and with ten-fold cross-validation, the receiver operating characteristic area under the curve, (ROC AUC) reached a value of 0.77 (compared to the random baseline of 0.5), meaning that the model has about 77 percent chance to distinguish the dead and alive classes correctly (in other words, being right eight out of 10 times). Having said that, the best predicting models have all found that Tommy Shelby will survive the last season.
After arriving at our big spoiling answer, we can also take a step further and try to figure out why the model predicted what it did, and how we could interpret that. More particularly, we can take a look at the different feature’s predictive power, visualized in Figure 2. This chart tells us that the two most important predictors were the level of negative sentiment in the character’s biography and the number of network connections (node degree) they have, with relative importances of 20 percent and 15 percent, respectively.

Conclusion and outlook
After collecting some simple, easy-to-access, both structured and unstructured data, it turns out that we can build a fairly accurate model to predict the fate of a major Peaky Blinders character. At first, this prediction exercise may seem to provide little practical importance – which is fine as it was completely inspired by personal interest and fun.
However, if we take one step back, this project also shows how (binary) machine learning prediction and the combination of different types of data can be used in (sometimes surprisingly) unusual settings. For instance, imagine that instead of the show we have an actual office or corporation, while the texts are CVs or emails, the connections are meetings or reporting relationships, and the predicted variables are salary raises, promotions, or even new hires. Can you imagine a practical application, now?
Limitations
As always, there are many limitations and shortcomings in this technique, besides the volume of the data source and complexity of the models used. For instance, the network part could certainly be improved by not only using embedded hyperlinks to establish the network connection, but by also performing more sophisticated name matching that can account for different name variants. Besides that, when comparing textual features, I assumed that measuring complexity and sentiment scores work homogeneously well for each text – which might not be true, because different editors may have different styles (e.g., more or less sarcastic). Additionally, directly channeling in the series (either visually or using the subtitles), or even meta-information about the actors, in addition to fan wiki data, could potentially enhance the modeling results. Finally, the model could have also been improved and fine-tuned, for instance, by increasing the number of characters included in the analysis by dropping fewer characters during the feature generation. This could have been done via either feature imputation (guessing the values of missing data points) or reducing the number of features (excluding those features that have the most missing values). The latter might also have a positive on my model’s performance against overfitting, which was currently handled by cross-validation only.

With a background in physics and biophysics, I earned my PhD in network and data science in 2020. I studied and researched at the Eötvös Loránd University and the Central European University in Budapest, at the Barabási Lab in Boston, and the Bell Labs in Cambridge. I am currently the chief data scientist of Datapolis, a research affiliate at the Central European University, a senior data scientist at Maven7, and a data science expert of the European Commission.
- Milán Janosov

- Milán Janosov

- Milán Janosov

- Milán Janosov





